캐시 메모리
CPU 동작을 단순히 표현하면 다음과 같은 동작의 반복이다.
1. 명령을 읽고 명령 내용에 따라 메모리에서 레지스터로 데이터를 읽음
2. 레지스터에 있는 데이터를 가지고 계산
3. 계산 결과를 메모리에 다시 저장
레지스터에서 처리하는 계산 시간에 비하면 메모리 접근 속도는 매우 느림. 예를 들어 레지스터 계산이 1회당 약 1 나노초 미만일때, 메모리 접근은 1회당 수십 나노초가 걸린다. 위의 처리 2번이 아무리 빠르더라도 1, 3번 메모리 read/write에서 병목 현상이 일어나서 전체 처리 속도가 느려지는 것이다.
해당 문제를 해결하기 방법으로 캐시 메모리가 있다. 일반적으로 캐시 메모리는 CPU 내부에 존재하는 고속 기억장치이다. 캐시 메모리에 접근하는 속도는 일반 메모리에 접근하는 속도에 비해 수배~수십배 빠르다.
메모리에서 레지스터로 데이터를 읽어 들일 때, 캐시 메모리에 캐시라인이라고 부르는 단위로 데이터를 읽어서 그 데이터를 레지스터로 옮긴다.
캐시라인 크기는 CPU마다 정해져있고, 해당 처리는 하드웨어에서 이뤄지기 때문에 커널에서 크게 관여하지 않는다.
다음과 같은 가상 CPU를 가정하고, 캐시 메모리가 하는 일을 생각해보자.
- 레지스터는 R0과 R1 두 종류이며, 둘 다 크기는 10바이트
- 캐시 메모리 크기는 50바이트
- 캐시라인 크기는 10바이트
우선 CPU의 R0에 메모리 주소 300의 데이터를 읽어온다.
이때 CPU가 주소 300의 데이터를 다시 읽는다면, 메모리에서 가져오는 대신에 캐시 메모리에 곧바로 접근하면 되니 빠르게 처리가 가능하다.
| 메모리 | 캐시 메모리 | CPU | ||||
| 주소 | 값 | 주소 | 값 | dirty | 이름 | 값 |
| 300 - 310 | XXX | 300 - 310 | XXX | O/X | 레지스터 R0 | XXX |
그리고 이때 R0에 쓰인 값을 변경하고, 메모리 주소 300에 반영한다면, 메모리에 쓰기 전에 캐시 메모리에 먼저 저장한다. 이후 캐시라인에는 데이터가 변경되었다는 것을 뜻하는 표시를 붙인다. 이런표시가 붙은 캐시라인을 dirty하다고 함.
이런 dirty표시가 붙은 캐시라인의 데이터를 메모리에 반영하면 캐시라인에 붙은 dirty표시가 사라진다.
메모리에 데이터를 쓰는 방법에 write-through와 write-back이 있는데,
- write-through => 데이터를 캐시 메모리에 씀과 동시에 메모리에도 바로 기록(구현이 상대적으로 간단)
- write-back => 나중에 정해진 때가 되면 기록함.(상대적으로 매번 write하지 않으니 처리 속도가 빠름)
캐시 메모리가 가득 찼는데, 캐시에 존재하지 않는 데이터를 읽어 들이면 기존의 캐시라인 중에 하나를 버리고 빈 캐시라인에 새로 데이터를 넣게 됨. 이때 버리는 캐시 라인이 더티 상태라면 메모리에 데이터를 저장하는 clean 처리를 하고 버린다. 이때 캐시 메모리가 가득 차있고, 캐시되지 않은 메모리 영역에 계속해서 접근하면, 캐시라인 내부 데이터가 빈번히 교체되는 thrashing 상태가 되어서 처리 성능이 떨어진다.
참조 지역성
만약 CPU가 사용하는 데이터가 전부 캐시 메모리에 존재한다면, CPU가 메모리에서 레지스터로 읽어오는 명령을 실행할 때 캐시 메모리 접근만으로 모든 처리가 끝날 것임. write-back 방식을 사용한다면 레지스터에서 메모리에 데이터를 쓰는 처리도 캐시 메모리에 작성하는 것이 끝이다.
많은 프로그램에서 참조 지역성이라고 하는 다음과 같은 특징이 존재한다.
- 시간적 지역성: 어떤 시점에 접근하는 메모리는 가까운 미래에 또다시 접근할 가능성이 높다. 반복 처리 내부에 존재하는 코드가 전형적인 예시임.
- 공간적 지역성: 어떤 시점에 메모리에 접근하면 가까운 미래에 그 근처에 있는 데이터에 접근할 가능성이 높다. 배열 요소 전체를 순서대로 조사하는 배열 데이터가 전형적인 예임.
따라서 프로세스가 메모리에 접근하는 모습을 관찰할 때 어떤 짧은 기간으로 한정하면, 프로세스 시작-종료까지 사용하는 메모리 총량에 비교했을 때 적은 메모리만 사용할 것이다. 이때 사용하는 메모리 용량이 캐시 메모리 용량으로 충분히 처리할 수 있으면 앞에서 말한 이상적인 고속처리를 기대할 수 있다.
계층형 캐시 메모리
최신 CPU는 캐시 메모리를 계층화된 구조 형태로 관리한다. 각 층을 L1/L2/L3 캐시라고 부른다. 레지스터에 가장 가까이 있는 캐시가 L1이고, 캐시 중 가장 빠르고 가장 용량이 적다. 계층 숫자가 늘어날수록 레지스터에서 멀어지고 용량이 늘어나지만 속도는 떨어진다.
캐시 메모리 정보는 /sys/devices/system/cpu/cpu0/cache/index0/ 디렉토리에 있는 파일 내용을 보면 확인할 수 있다.
파일 내용 일부를 보면 아래와 같다.
| 파일명 | 의미 |
| type | 캐시할 데이터 종류. Data라면 데이터, Instruction이라면 코드, Unified라면 코드와 데이터 모두 캐시함 |
| shared_cpu_list | 캐시를 공유하는 논리 CPU 목록 |
| coherency_line_size | 캐시라인 크기 |
| size | 크기 |
Simultaneous Multi Threading(SMT)
CPU의 계산 처리 소요 시간보다 메모리/캐시 메모리의 접근시간이 훨씬 더 길다. 따라서 time 명령어의 user나 sys에 포함되는 CPU 사용 시간 중 많은 부분이 메모리 또는 캐시 메모리에서 데이터 전송을 기다리기만 하고 CPU 계산 자원은 놀고 있는 상태인 경우가 많다.
데이터 전송 대기 이외에도 CPU 계산 자원이 놀고있는 케이스가 있는데, 예를 들어 CPU에 정수 연산/부동 소수점 연산하는 유닛이 존재하는데, 정수 연산을 하는 동안은 부동 소수점 연산 유닛은 놀고 있는 상태가 된다.
이런 비어 있는 자원을 하드웨어의 Simultaneous Multi Threading(동시 멀티스레딩) 기능으로 유용하게 활용할 수 있다. SMT에서 말하는 thread는 프로세스에서 말하는 thread와 전혀 별개의 단어이다.
SMT는 CPU 코어 내부에 있는 레지스터 등의 일부 자원을 여러 개(ex - CPU2개) 만들어서 각각을 스레드로 삼는다. 리눅스 커널은 이렇게 만든 각 스레드를 논리 CPU로 인식한다. 하나의 CPU에 t0, t1 이렇게 2개의 thread가 있고, t0에는 프로세스 p0, t1에는 프로세스 p1이 동작한다고 하자. t0에서 p0이 동작하고 있을 때 CPU에 어떤 자원이 비어 있다면 t1의 p1은 그 자원을 사용해서 처리를 먼저 진행할 수 있다. 운 좋게도 p0와 p1 사이에 사용하는 자원이 겹치지 않는다면 SMT 효과가 더욱 커진다.
예를 들어 p0는 정수 연산만 실행하고 p1은 부동 소수점 연산만 실행하는 상황이다. 빈번하게 사용하는 자원이 겹친다면 SMT 효과가 작아지고, 오히려 SMT를 사용하지 않을 때보다 성능이 나빠질 가능성도 있다.
Translation Lookaside Buffer(변환 색인 버퍼)
프로세스가 어떤 가상 주소에 있는 데이터에 접근하려면 다음과 같은 순서를 따라야 한다.
1. 물리 메모리에 존재하는 페이지 테이블을 참조해서 가상 주소를 물리 주소로 변환한다.
2. 1에서 얻은 물리 메모리에 접근한다.
캐시 메모리를 쓰면 2가 빨라진다는 건 맞는데, 1은 여전히 메모리에 있는 페이지 테이블에 접근해야하므로, 캐시메모리를 사용해도 그 효과를 최대한으로 살릴 수 없다.
이런 문제를 해결하기 위해 CPU에는 TLB영역이 존재한다. TLB는 가상 주소를 물리 주소로 바꾸는 변환표를 저장하고 있어서 1을 고속으로 처리할 수 있다.
페이지 캐시
CPU에서 메모리에 접근하는 속도에 비해, 저장 장치에 접근하는 속도는 훨씬 느리다. 특히 하드 디스크 같은 경우라면 1000배 이상 느리기도 한데, 이런 속도 차이를 줄이기 위해 커널은 페이지 캐시를 사용한다.
페이지 캐시는 캐시 메모리와 닮았는데, 캐시 메모리는 메모리 데이터를 캐시하는 반면에, 페이지 캐시는 파일 데이터를 메모리에 캐시한다. 캐시 메모리는 캐시라인 단위로 데이터를 다루지만, 페이지 캐시는 페이지 단위로 데이터를 다룬다. 그외에도 페이지의 더티 상태를 표시하는 dirty page, 더티 페이지를 디스크에 다시 쓰는 write-back 개념도 존재한다.
프로세스가 파일 데이터를 읽기 시작하면 커널은 프로세스 메모리에 파일 데이터를 직접 복사하는 대신에 일단 커널 메모리에 있는 페이지 캐시 영역에 복사해두고, 해당 데이터를 프로세스 메모리에 복사한다.
| disk의 file A | 메모리 | ||
| 주소 0 - 100 | data XXX | 커널 메모리 영역 | |
| 주소 200 - 300 | data XXX | ||
| 프로세스 메모리 영역 | |||
| 주소 800 - 900 | data XXX | ||
추가로, 커널은 페이지 캐시에 캐시한 영역의 관련정보를 관리하는 영역도 커널 메모리 안에 둔다.(아래 내용이 커널 메모리안에 들어간다.)
| 파일명 | 파일 오프셋 | 메모리 주소 |
| A | 0 - 100 | 200 - 300 |
혹시 해당 프로세스 말고, 다른 프로세스가 페이지 캐시에 존재하는 data를 또 읽는다면, 커널은 저장 장치에 접근하는 대신에 페이지 캐시에 있는 데이터를 돌려주므로 빠르게 끝난다.
캐시 메모리 방식과 마찬가지로, 프로세스가 데이터를 파일에 쓰면 커널은 페이지 캐시에만 데이터를 기록한다. 이때 데이터 내용이 저장 장치에 있는 것보다 최신이라는 표시를 관리 영역 내부의 변경된 페이지 관련 항목에 남긴다. 이런 표시가 있는 페이지를 dirty page라고 부른다.
페이지 캐시를 사용하면 쓰기 작업도 읽기처럼 저장 장치에 접근할 때보다 빨라진다. 특정 타이밍에 저장 장치에 반영되게되고, 이후 더티 페이지 표시가 지워지는 write-back 처리로 핸들링 된다.
만약 페이지 캐시에 더티 페이지가 존재하는 상태에서 갑자기 전원이 꺼진다면? 해당 페이지 캐시에 있는 data는 사라진다. 이런일을 방지하기 위해서 open() system call로 파일을 열 때 O_SYNC 플래그를 설정하면, write-through 방식으로 페이지 캐시, 저장 장치에 동시 기록을 할 수 있다.
buffer cache
페이지 캐시와 비슷한 버퍼 캐시가 있다. 버퍼 캐시는 disk의 데이터 중에서 파일 데이터 이외의 것을 캐시하는 방식이다. 버퍼 캐시는 다음과 같은 목적으로 사용한다.
- 파일 시스템을 사용하지 않고 디바이스 파일로 저장 장치에 직접 접근할 때
- 파일 크기나 권한 등의 메타 데이터에 접근할 때
버퍼 캐시도 페이지 캐시와 마찬가지로 버퍼 캐시에 쓴 데이터가 아직 디스크에는 반영되지 않은 더티 상태가 존재한다. 예를 들어 어떤 장치에 파일 시스템이 존재하고 그 파일 시스템을 마운트한 상태라고 가정하자. 이때 장치의 버퍼 캐시와 파일 시스템의 페이지 캐시는 서로 다른 존재이므로 동기화도 하지 않는다. 따라서 예를 들어 파일 시스템을 마운트하고 있을때
dd if=<파일 시스템에 대응하는 장치의 디바이스 파일명> of=<백업 파일명> 명령어로 디스크 백업을 만들면 파일 시스템의 더티 페이지 내용은 백업 파일에 반영되지 않는다. 이런 문제를 피하려면 파일 시스템 마운트 중에는 대응하는 디바이스 파일에 접근하지 않는 것이 좋다.
쓰기 타이밍
더티 페이지는 보통 백그라운드로 동작하는 커널의 write-back 처리에 따라 디스크에 저장된다. 동작 타이밍은 다음 두 종류이다.
- 주기적으로 동작. 기본값은 5초마다 1회
- 더티 페이지가 늘어났을 때 동작
write-back 주기는 sysctl의 vm.dirty_writeback_centisecs 파라미터로 변경할 수 있다. 단위는 센티초(1/100초) 이다.
파라미터 값을 0으로 지정하게되면 주기적인 write-back이 무효화된다. 하지만 갑자기 전원이 꺼지거나 하면 큰 영향이 가기 때문에 실험 용도 등이 아니라면 굳이 건드리지 않는 것이 낫다.
시스템에 설치된 전체 물리 메모리 중에서 더티 페이지가 차지하는 비율이 vm.dirty_background_ratio 파라미터로 지정한 비율(%단위)을 넘기면 write-back 처리가 동작한다.
바이트 단위로 지정하고 싶다면 -> vm.ditry_background_bytes 파라미터 사용(기본값은 미설정을 뜻하는 0)
더티 페이지가 계속 늘어서 vm.dirty_ratio 파라미터로 지정한 비율(%단위)을 넘기면 파일 쓰기 처리의 연장으로 동기적으로 데이터를 디스크에 기록한다. 바이트 단위로 지정하고 싶으면 마찬가지로 vm.dirty_bytes 사용.
더티 페이지가 많은 생기는 시스템에서는 메모리가 부족해서 더티 페이지의 write-back이 자주 발생하면 시스템이 멈추거나 더 심하면 OOM이 발생하는 경우가 수두룩하다. 더티 페이지 관련 파라미터를 잘 조정해서 해당 문제를 예방할 수 도 있다.
직접 입출력
대부분의 경우라면 페이지 캐시나 버퍼 캐시가 유용하지만, 다음과 같은 상황에서는 없는 편이 나을 수 있다.
- 한 번 읽고 쓰면 두번 다시 사용하지 않는 data, 예를 들어 어떤 파일 시스템의 데이터를 USB같은 이동식 저장 장치에 백업한다면 백업 대상 저장 장치는 백업이 끝나면 곧바로 시스템에서 제거하므로 페이지 캐시를 할당할 의미가 없다. 이런 데이터를 페이지 캐시하기 위해서 유용한 다른 페이지 캐시를 해제하는 경우도 있다.
- 프로세스가 자체적으로 페이지 캐시에 해당하는 기능을 구현한 경우
이럴 때에는 직접 입출력 direct I/O 방식을 사용하면 페이지 캐시 없이 처리할 수 있다. 직접 입출력을 사용하려면 파일을 대상으로 open() 할 때, O_DIRECT 플래그를 지정한다.(만약 입출력 완료를 기다리고 복귀하려면 sync 옵션도 추가하면 된다.)
SWAP
스터디 4에서 사용 가능한 물리 메모리가 없어지면 OOM 상태가 된다고 설명했다. 하지만 SWAP 기능을 사용하면 메모리가 고갈되어도 곧바로 OOM이 발생하는 것을 방지할 수 있다.
SWAP은 저장 장치 일부를 임시적으로 메모리처럼 사용하는 방법이다. 구체적으로는 시스템의 물리 메모리가 고갈 상태일 때 더 많은 메모리를 확보해야 한다면 사용 중인 물리 메모리 일부를 저장 장치로 옮기고 메모리에 빈 공간을 만든다.
이때 데이터를 옮긴 영역을 swap 영역이라고 부른다.
물리 메모리가 고갈된 상태에서 프로세스 B가 물리 메모리에 담겨 있지 않은 가상 주소 100에 접근해서 page 폴트가 발생했다고 가정하자.
이때 물리 메모리 내부에서 한동한 사용되지 않을 거라고 커널이 판단한 메모리를 스왑 영역으로 옮겨서 기록한다. 이 처리를 page out / swap out 이라고 한다. 커널에서 대피시킨 페이지 스왑 영역(프로세스 A의 페이지를 swap했다고 가정하)을 기록해두고, 비워둔 메모리를 프로세스 B에 할당한다.
이후, 메모리 빈 공간이 생긴 상황에서 프로세스 A가 앞서 page out 한 페이지에 접근하면 대응하는 데이터를 다시 메모리로 읽어 온다.(page in / swap in)이라고 부른다.
프로세스 A 페이지 테이블
| 가상 주소 | 물리 주소 |
| 0 - 100 | 500 - 600 |
| 100 - 200 | swap 영역의 0 - 100 (disk로 넘겨짐, 이후 접근시 다시 읽어옴) |
페이지 폴트 중에서 page-in 때문에 저장 장치에 접근이 발생하는 것은 major fault, 그외는 minor fault 라고 한다. 둘 다 커널 내부 처리가 동작해서 성능에 영향을 주지만 메이저 폴트 쪽이 훨씬 영향도가 크다.
swap을 사용하면 명목상 시스템에서 사용 가능한 메모리 용량이 실제로 설치된 물리 메모리 + swap 영역만큼 늘어나므로 좋은 것 처럼 보이지만 큰 문제가 있다. 저장 장치에 접근하는 속도는 메모리 접근 속도에 비해 매우 느리기 때문이다.
시스템 메모리 부족 현상이 일시적인 것이 아니라 늘 부족한 상태라면 메모리 접근을 할 때마다 page-in, page-out이 반복되는 thrashing 상태(가상 메모리 처리에 과부하가 생겨서 CPU, OS가 페이징 처리 능력에 대부분을 소비하는 상태)가 된다. thrashing이 발생하면 그대로 동작이 멈추거나 OOM이 발생한다.
통계 정보
$ sar -r 1 5 # 5초동안 1초 간격으로 메모리 정보 데이터 수집
Linux 5.4.-74-generic (coffee) 12/04/2021 _x86_64_(8 CPU)
03:08:24 PM kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
03:08:25 PM 4225432 5460160 1397816 18.09 67080 1869944 6410488 65.24 722640 2019192 152
...| 필드명 | 의미 |
| kbmemfree | 비어 있는 메모리 용량(KiB 단위). 페이지 캐시나 버퍼 캐시. 스왑 영역은 포함 X |
| kbavail | 사실 상 비어 있는 메모리 용량(KiB 단위). kbmemfree에 kbbuffers와 kbcached를 더한 값. 스왑 영역 포함 X |
| kbbuffers | 버퍼 캐시 용량(KiB 단위) |
| kbcached | 페이지 캐시 용량(KiB 단위) |
| kbdirty | 더티한 상태의 페이지 캐시와 버퍼 캐시 용량(KiB 단위) |
예를 들어 kbdirty 값이 평소보다 크다면 조만간 동기적으로 write-back 처리가 실행될 가능성이 있다.
sar -B 명령어를 사용하면 페이지 인과 페이지 아웃 관련 정보를 확인할 수 있다. page cache, buffer cache가 disk와 데이터를 주고 받 것도 똑같이 page-in, page-out이라고 부른다.
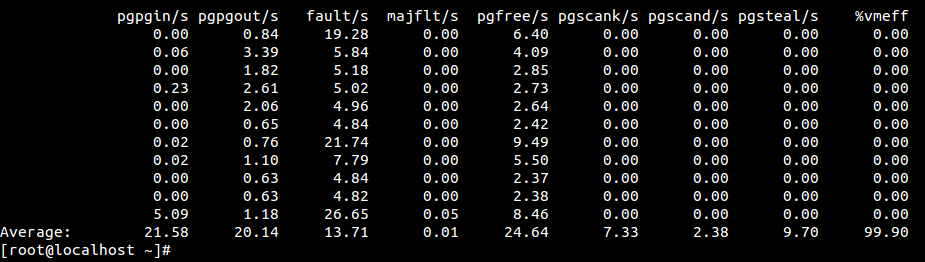
| 필드명 | 의미 |
| pgpgin/s | 초당 page-in 데이터량(KiB 단위). page cache + buffer cache + swap 다 포함 |
| pgpgout/s | 초당 page-out 데이터량(KiB 단위). page cache + buffer cache + swap 다 포함 |
| fault/s | 페이지 폴트 수 |
| majfit/s | 페이지 폴트 중에서 page-in이 일어난 수(major fault) |
시스템의 swap 영역은 swapon --show 명령어로 확인할 수 있다.
NAME TYPE SIZE USED PRIO
/swapfile file 2G 512M -2
/dev/sda2 partition 4G 1G -1size를 통해 swap 공간의 총 크기를 알 수 있다.
또한 free명령어에 나오는 Swap: 라인이 스왑 영역 정보이다.
sar -W 1(초마다) 명령어를 통해 지금 스왑이 발생하고 있는지 알 수 있고, sar -S 명령어를 사용하면 스왑 영역 이용 상황을 알 수 있는데, 해당 명령어에서는 보통 kbswpused 필드에 표시되는 스왑 영역 사용량 추세를 보면된다. 해당 값이 점점 늘어난다면 위험하다는 뜻이다.
'Linux' 카테고리의 다른 글
| RPM build .pc 파일과 pkgconfig 의존성 정리 (0) | 2025.05.15 |
|---|---|
| File descriptor란? process 간 공유에 대하여 (0) | 2025.03.15 |
| 리눅스 스터디 #7 파일 시스템 (0) | 2025.01.19 |
| 리눅스 스터디 #6 장치 접근 (0) | 2025.01.19 |
| 리눅스 스터디 #5 프로세스 관리(응용) (0) | 2025.01.19 |